
 项目商机
项目商机 知识锦囊
知识锦囊 数智工具
数智工具 专家顾问
专家顾问 机器人互动营销解决方案
机器人互动营销解决方案 品牌私域会员服务站系统
品牌私域会员服务站系统 AI大模型数字人员工方案
AI大模型数字人员工方案 企微SCRM客户管理系统
企微SCRM客户管理系统 新零售电商平台解决方案
新零售电商平台解决方案 全员营销电子名片系统
全员营销电子名片系统 AIGC绘画打卡机引流方案
AIGC绘画打卡机引流方案 门店私域会员服务小站
门店私域会员服务小站 公司简介
公司简介 联系合作
联系合作
 复制链接
复制链接 微信
微信 QQ
QQDeepSeek-VL系列是一款由DeepSeek-AI团队开发的开源视觉-语言(Vision-Language, VL)模型,旨在解决真实世界中的视觉和语言理解任务。以下是DeepSeek-VL系列的主要功能和应用场景:

DeepSeek-VL系列具备强大的多模态理解能力,能够处理包括逻辑图表、网页、公式识别、科学文献、自然图像等多种复杂场景。它通过混合视觉编码器和语言适配器,可以高效地处理高分辨率图像(如1024x1024像素),并捕捉图像中的细节信息和语义内容。
视觉问答(VQA)
DeepSeek-VL在视觉问答任务中表现出色,能够根据图像内容回答问题。例如,它可以识别图像中的对象,并结合上下文信息生成准确的回答。
文档/表格/图表理解和处理
模型支持对文档、表格和图表的解析与理解,能够从图像中提取关键信息并进行分析。这在OCR(光学字符识别)和文档分析等任务中表现尤为突出。
视觉定位
DeepSeek-VL能够根据文本提示定位图像中的特定对象或区域,例如在一张图片中找到并标注出目标位置。这一能力使其在自动驾驶、机器人导航等领域具有潜在应用价值。
图像生成与编辑
模型可以基于用户需求生成或编辑图像。例如,它可以根据用户的描述重新绘制图片,并提供详细的解释,这对于学术研究和创意设计非常有用。
跨模态检索与推荐
DeepSeek-VL支持跨模态检索任务,例如通过图像或文本检索相关的内容。这种能力使其在电商、社交媒体内容推荐等领域具有广泛的应用前景。
零样本学习能力
模型在零样本设置下仍能表现出良好的性能,这意味着它可以在未见过的数据上快速适应并完成任务。
开源与社区支持
DeepSeek-VL系列是开源的,开发者可以通过官方提供的教程和工具包快速上手使用。此外,该模型还支持大规模数据集的微调,以适应特定的应用场景。
性能与效率
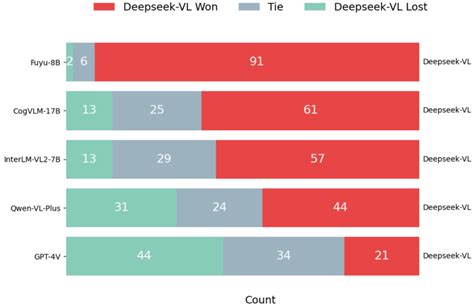
DeepSeek-VL系列模型在多个基准测试中超越了同类模型,如LLaVA-Next、Qwen-VL-Chat等,在视觉语言任务中展现了卓越的性能。同时,其高效的计算策略降低了资源消耗,使其更适合实际部署。
商业应用潜力
DeepSeek-VL系列不仅适用于学术研究,还具备广泛的商业应用潜力。例如,在自动驾驶、智能客服、内容生成、电商推荐等领域,DeepSeek-VL都可以提供强大的技术支持。
DeepSeek-VL系列是一款功能强大且灵活的多模态大模型,能够在多种真实世界场景中实现高效、准确的视觉和语言理解。其开源特性进一步推动了AI技术的普及和创新,为研究人员和开发者提供了强大的工具。







